Yes, there is a new Textbase on the market in the AI area. But our Textbase.scriptorium.ro is older so we’re going to stick to the name. It’s really ours.
Because Textbase is really what its name says: a text database. Yet another pile of ebooks, I hear you say. On the one hand, yes Textbase is also a pile of ebooks: and those ebooks are going to be soon even more impressive — you’ll be able to get (beautiful) PDFs or Epubs etc. formats. That’s what other digital libraries are too, right? Elaborate, HTML linked piles of ebooks.
#Textbase is actually more: it is a queryable text database. Our XML is not your weekly invoices, not log data converted from JSON — but literary masterpieces, in some cases, immortal works of art. So we’re serving not any XML but prestigious XML (TEI to be exact) — in that XML you have Hugo’s thought, Shakespeare’s dreams, Miron Costin’s views.
Most digital databases of ebooks are not structured today. Although XML came and left the stack of software’s coolest technologies — most queryable digital libraries are still experimental. There are a few reasons to that but we’ll leave that analysis for another moment.
On our side, we’re making Textbase even more queryable. Right now you can write, for example:
https://textbase.scriptorium.ro/cosbuc/cantece_de_vitejie/sus_inima
and get a poem from the Romanian poet named George Coșbuc. URL slugs are really a beauty. They are generated from <div>s heads using infinitely detailed rules with lots of hand-written exceptions.
We will soon, hopefully, have even a CLI interface to #textbase so that you can browse with auto-completion authors, works, chapters and so on. As of today, there is an alpha fuse interface to textbase, named textbase-fs which is hosted on github. Yes, you can mount the Textbase content as a filesystem in userspace mount. Download it, try it, improve it.
#Textbase will be open source. The Java software that serves excerpts of XML will be open source and I would do it right now if I did not have to finish a few new evolutions first. It will be open source because there is so much quality in those texts we’re serving, that we got from PG, Gallica and other sites, that we must provide the serving software also as a free service. It seems the right thing to do. We’ll try to develop annex services for clients that need particular or related services for money.
So we’re adding new features.
Universal identifiers. A number-sequence schema that can identify any XML piece, excerpt, chapter, subchapter, paragraph, sentence — and even a letter. As a first example, you will be able to ask textbase for /cosbuc/cantece_de_vitejie/1.
It seem simple but it is really not. That would mean the first thing under cantece_de_vitejie. Chapters, subchapters, poems and such, are stored in TEI as <div>s. But as it happens a chapter can have a sub-element which is not a div, but just plain text, or some <p>aragraph or table or anything else. We cannot guarantee that a div (chapter) has only pure div children. It may have text excerpts etc, although, to be fair, most Textbase content serves books which have either leaf-chapters (that is a chapter full of text) or empty container-chapters — that is divs that contain other divs.
That is the most frequent case but it is not compulsory. It may well happen that a div contains three paragraphs, some whitespace and then a div and then another div and then some final text. It should be rare, but not impossible except that we’re running a software server so we need to account for general situations.
Now the most general situation would be that in which we would store the entirety of our TEI XMLs in a dedicated XML server like existdb for example. We will do that, ne serait-ce que for the sake of seeing what’s possible. Existdb is an XML database queryable by also a REST API, which for a queryable repository, is quite important.
Still, we want search to be extremely easy. We do not want to ask users to learn xpath or xquery for getting their content. We really want people to go the textbase and ask for /shakespeare/julius_caesar and get something meaningful. That is not xpath, that is just commons sense, and we like common sense.
But xpath is more universal. With xpath you can get any excerpt, even those that textbase does not deem important for rendering, for example.
So up to now, if you asked Textbase for https://textbase.scriptorium.ro/shakespeare/macbeth_3/act_i/1 it would get you the first scene of the require act. Note the final 1. Now try with 2. It works. It gets you the third subdiv though. That is because the div counting starts at zero. https://textbase.scriptorium.ro/shakespeare/macbeth_3/act_i/0 — this is the real first scene of the english shakepseare version of Macbeth. It is named macbeth_3 because chance would have it that the german and french translations are parsed first when inspecting the TEI file listings. Of course we should reserve the macbeth/ path for the original english version and this is a feature that we need to add at some point. The algorithm right now parses TEI files in tree-walk directory listing order and at some point this improvement will be added.
So what’s the evolution: number will be possible in the URL, even necessary. That is because only <divs> are identifiable by their <head>s ? <head> in TEI XML is the corresponent of <h1>, <h2>… in HTML. Regular element like <p>, like <lg> (for verses) like <speaker> for drama, do not have <heads> that we can use to beautifully identify. Some sort of identification in necessary. A simple one uses numbers for identifying the number of the XML subelement.
So when a number will be typed in URL, its meaning is clear: once identified as a number. A disambiguation will be necessary. Number can also be <head>s of <divs>. A div can be called 1, and it is actually a recurring case of chapters which are numbered. So /head/subhead/1 can be a valid identifier of a head.
So we need a special scheme for getting explicit arbitrary sub-element of an element denoted by a path. That scheme will be using hash for example: #1. Underscore_number cannot naturally occur in head titling since on parse, heads are trimmed. A test must prove that special cases do not pass unexamined.
As such, having a /path/#n/ in the path will ask the controller to serve the nth element of /path. That nth element is numbered in xpath style, that means first element is numered 1, rather that the customary 0-starting indexes on C/Java lists/arrays.
Also, when meeting a #n, there will be an inspection on the XML corresponding of the /path. The nth child of /path will be selected. The nth child may be a <div> or not. If it is a <div>, it is already parsed into the database so a lookup into the database by the corresponding xpath will be done and the div retrieved, and the parsing of the path can continue with other sub-heads, like for example /path/_2/head/subhead — this will work if the _2nd element of /path is a <div> — it will throw exception otherwise because a <p> has no head and the ulterior selection head/subhead would only work for divs. So in the case where _2 denotes a <div> the path will actually return the corresponding XML excerpt.
Of course you can depass the limit of divs, given that you do no longer use <head> as url fragments. You can ask for /path/div/leaf/#1/#2/#3. In the case where leaf is the bottom-most leaf <div>, #1 would maybe point to an <lg> which might have a second <l> which might have a third <span>. These are no longer <divs> (chapters and subchapters). So you would be capable of identifying arbitrary elements by there simple position as a child of their parengo.
This in fact will become the generic XML-excerpt identification schema for textbase.
Why do we need to identify arbitrary subchapters and sub-elements of literary works.
Because it is cool.
Semantic links. But not only that. In the era of #AI, we’re not going to impress anyone with our xpath-friendly complement. What might actually create an impression is the reason why we need that feature. We need it because we need to create logical semantic links inside Textbase between arbitrary paragraphs and elements. That is say, given a paragraph we want to be able to click on it and get its closest other paragraphs, meaning-wise. We need to get the closest thing to any given paragraph, sentence, chapter, subchapter. Because our texts are not any texts but the treasures of humanity. So we want to click on a paragraph and get a list of links of close paragraphs from completely unrelated works. In order to do that we need to identify an arbitrary piece of TEI XML, which can be a <div>, a <p>, a <l>, a <table> and so on.
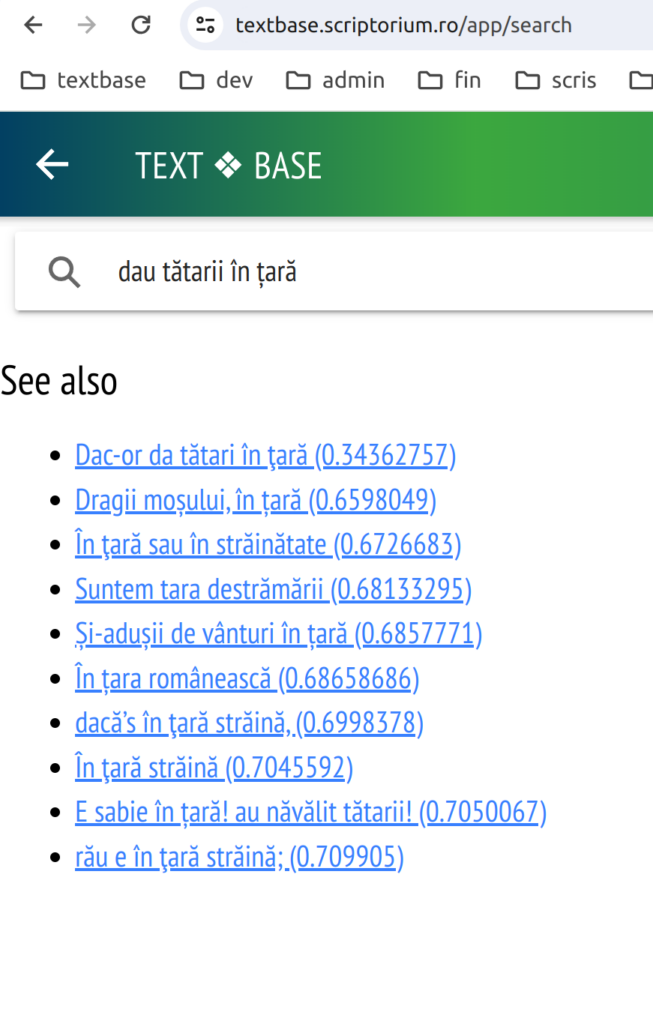
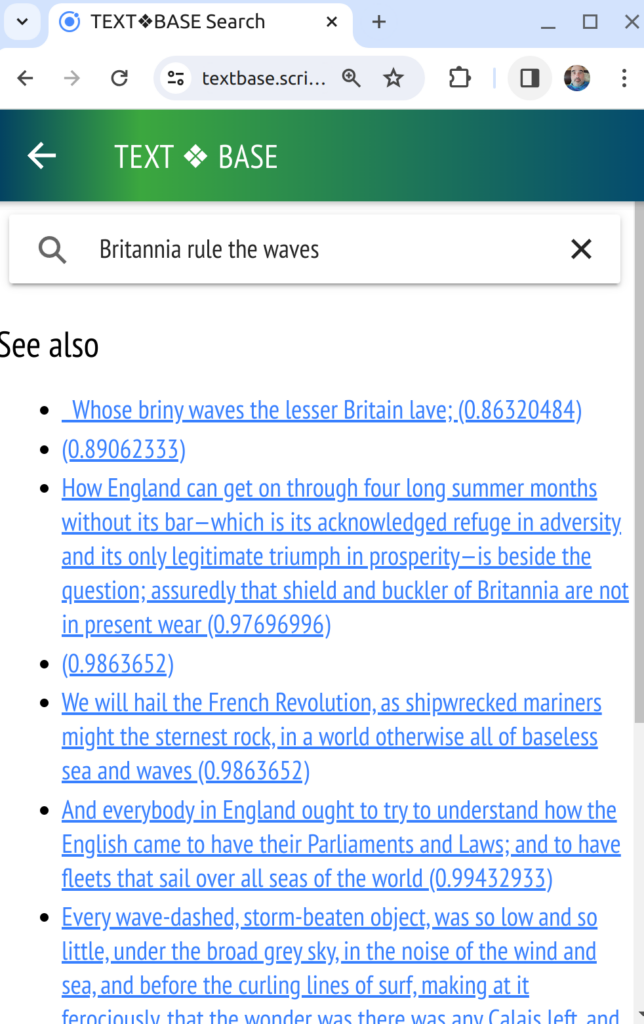
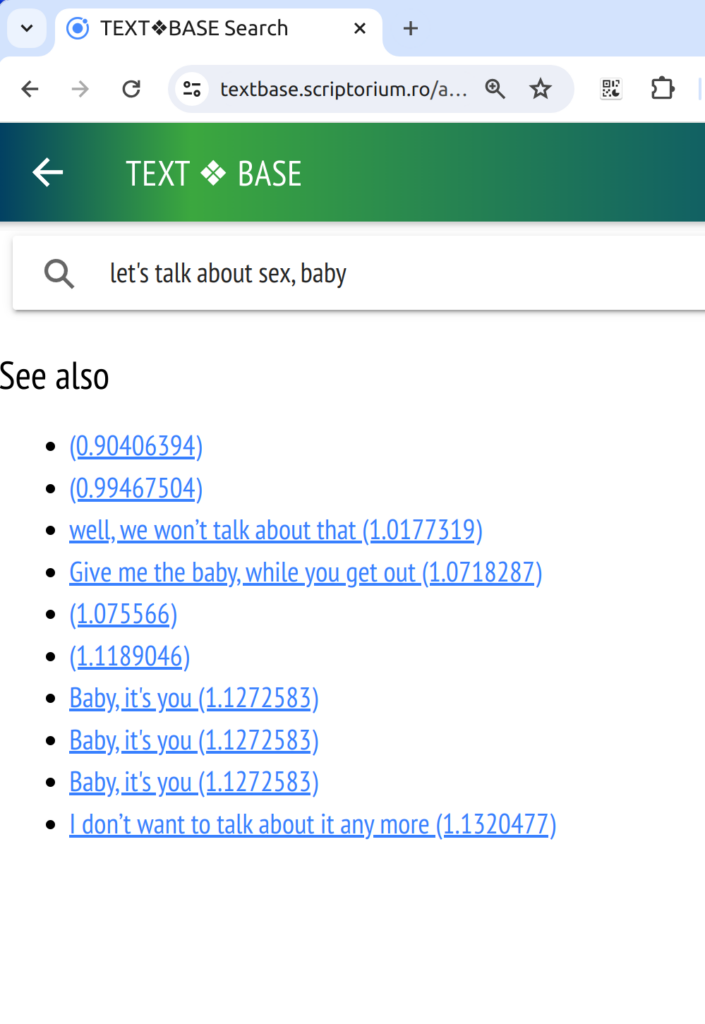
We have already implemented a pre-alpha version of this in the search feature of the Textbase app. The inconspicuous ‘See also’ links on the Search page, are actually retrieved using vector embeddings stored in Milvus and computed using SentenceTransformers models. We can use ever-improving models — for now we only just tried the idea with the all_mini model that the hello world SentenceTransformers uses. We’ll try more powerful models.
There. This is what we want to do for the next version of Textbase, 0.7.3. We’re at our wits end because on working with texts all our friends that we so love and are represented in our digital library tend to wake up and we do need some time off. But, times being as they are, we are grateful to work on interesting and innovative aspects.